Workflows de ML simplificados com o Cadence
Execute seu código em um hardware potente na nuvem, diretamente a partir do PyCharm, em questão de minutos, sem precisar de configurações complexas ou conhecimento da tecnologia de nuvem

Por que equipes de ML/IA devem escolher o Cadence?
Soluções de GPU escaláveis
Você pode ajustar recursos instantaneamente com a plataforma neutra em nuvem do Cadence e acessar uma ampla gama de GPUs disponíveis globalmente.
Uso otimizado de GPUs
O Cadence gerencia a alocação de recursos durante o treinamento, garantindo que GPUs sejam usadas apenas quando necessário.
Faturamento transparente
O Cadence adota um modelo de pagamento por uso, oferecendo gastos transparentes e controle detalhado sobre o consumo de recursos.
Colaboração aprimorada
O Cadence permite compartilhar e reutilizar facilmente os resultados dos experimentos com seus colegas, economizando o tempo de todos e permitindo que trabalhem de forma mais eficaz como equipe.
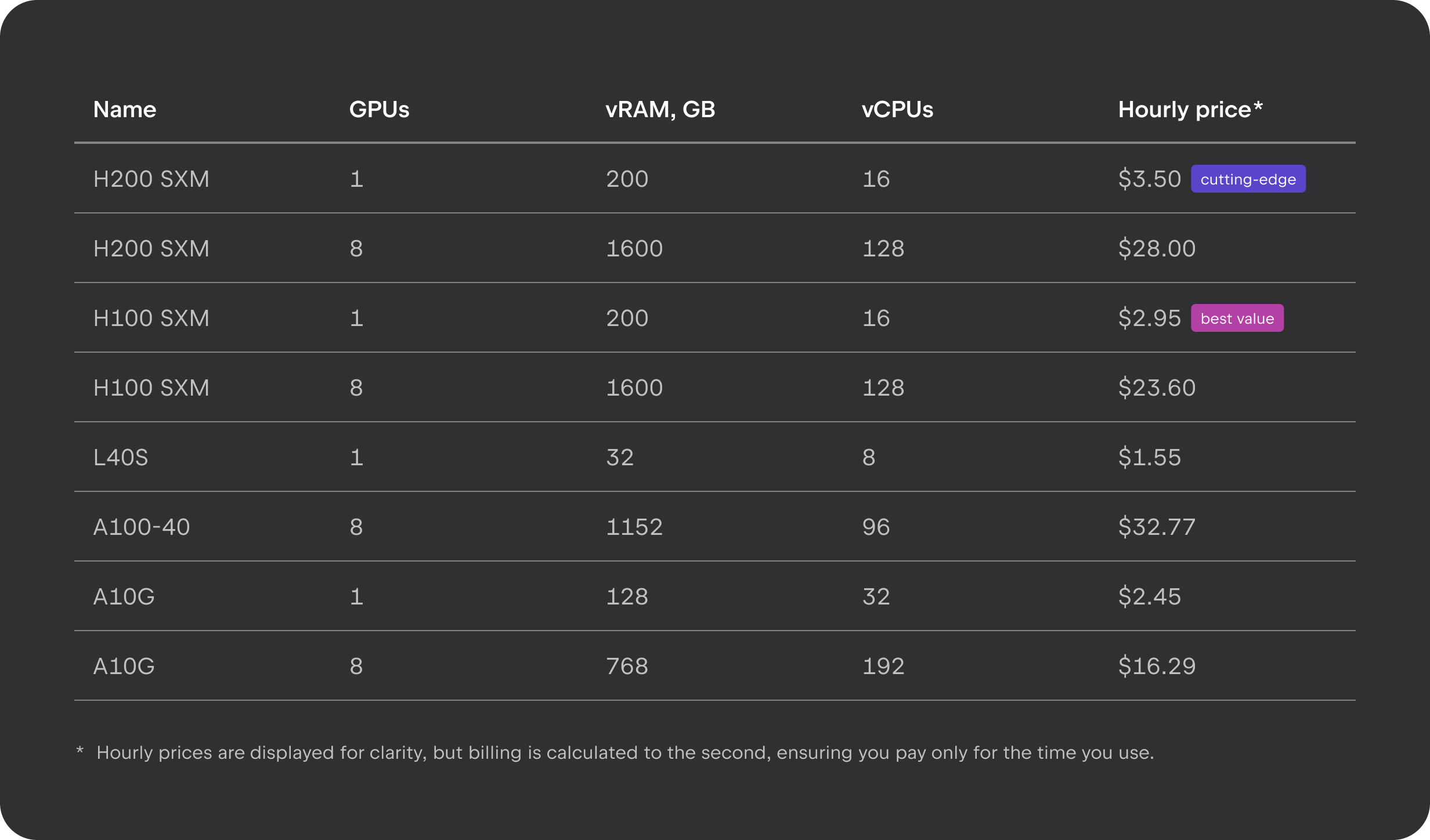
Planos e preços